Get in Touch
Take the first step towards enhancing your organization’s security. Contact us now or schedule an appointment for a consultation with our experts!

The terms in this document have been derived from the Disaster Recovery Journal (https://drj.com/resources/drj-glossary-of-business-continuity-terms/) and NIST (https://csrc.nist.gov/glossary/term/NIST) and various information to aid teams with implementing the appropriate resiliency components.
DR, BC, FT, and HA are all about Resilience. These key topics focus on maintaining operations during a crisis or returning to operations after a disruptive business impact. Think of Operational Resilience as the repeated actions, services, solutions, technologies, steps, processes, procedures, plans, and policies that outline what to do when a disruption occurs.
High Availability (HA) is often confused with Disaster Recovery (DR). HA is a component of DR. When a system has High Availability, it is Fault Tolerant (FT), or it can “failover.” By having such redundancies built into the system, it can immediately switch over to the redundant source. Just because a system, infrastructure, solution, or network is designed to have High Availability, it may fail to achieve the goal of Disaster Recovery. High Availability is the ability of a system to switch over to a redundant system when there is a component failure. In the case of DR, resources, and activities are used to restore services to normal operations in the shortest possible time by using an alternative production site, the cloud, or some other mechanism. HA is simply then a component of DR.
Fault Tolerance ensures availability by keeping copies on a separate host machine. For example, with HA on VMWare, the hypervisor attempts to restart the Virtual Machine (VM) on the same host cluster. If the physical system has other problems (power, network, etc.), HA may not work because the system itself may have hardware issues. So, with FT, the VM workload is moved to a completely separate host, or in the case of Microsoft Azure, the entire system would move to a different Availability Zone.
DR generally replaces an entire data center, whether physical or virtual. HA deals with faults in a single component like power or a single server rather than a complete failure of all IT infrastructure, which would occur in the case of a catastrophe. DR goes beyond FT and HA and consists of a comprehensive plan to recover critical systems and normal operations in the event of a catastrophic disaster (such as hurricanes, floods, tornadoes, cyberattacks, or any event that causes significant downtime). HA is often a major component of DR, which can consist of an entirely separate physical infrastructure site consisting of 1:1 replacement for every critical infrastructure component or as many as is required to restore the essential business functions.
Backups are also different from Disaster Recovery. Backups are a copy of data at a specific moment in time that is stored in the event of data loss, corruption, etc., where it can be restored.
For simplicity, FT is a subset of HA, Backups are a subset of DR, HA is a subset of DR, and DR is a subset of BC.
The critical difference between DR and BC is when the plan takes effect. Business Continuity (BC) requires the organization to keep operations functional during the event and immediately after. Disaster Recovery focuses on how the organization responds after the event has been completed and how to return to normal. In simple terms, BC is how to keep operational during a disaster, and DR is what to do once the disaster occurs and how to return to normal operations after the event.
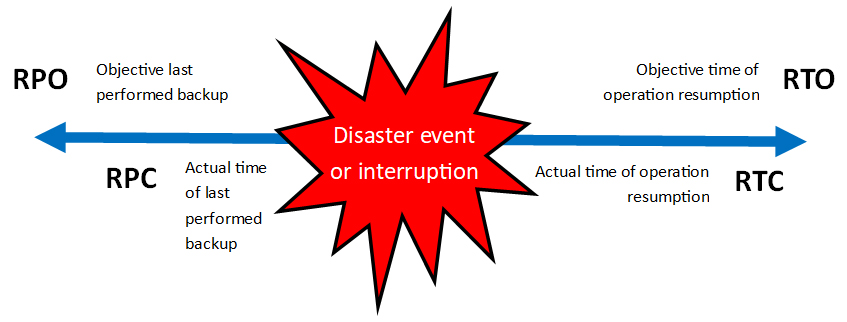
Time to restore backups. Usually shooting for less than 24 hours per backup item. The maximum time it takes for IT resources to recover a single or subset of files. Time is dependent upon the size of the data to be recovered. This is independent of RTO and RPO since it focuses on backup recovery, not disaster recovery.
Take the first step towards enhancing your organization’s security. Contact us now or schedule an appointment for a consultation with our experts!
© All Copyright 2023-2026 by Vanguard Technology Group